
python爬虫初探
声明:本文记录使用python抓取数据过程,仅供学习!
1. 背景
爬虫的原理总的来说就是向目标网站发送请求,然后根据需要过滤返回的数据,问题关键在于如何提取数据和破解目标网站反扒。
主要有两个思路
一是通过抓包分析获取相应取数据的api,大网站一般需要逆向模拟加密算法, 优点是取到的数据纯粹,缺点是需要分析代码,算法更新之后需要重新定分
二是模拟用户点击浏览器的操作,再配合分析工具提取数据,优点是简单方便,缺点执行比较慢
以下记录个人提取指定视频点赞数的学习过程
2. 环境安装
- 下载python
- 下载pythoncharm
- pycharm 安装 pyinstaller(需要打包exe的话)
- pip install pyinstaller
- pyinstaller -F {target.py}
3. 方案一
- 抓包分析
- 打开网页,打开浏览器开发者工具,找到网络,逐个分析想要的数据是哪个请求得到的
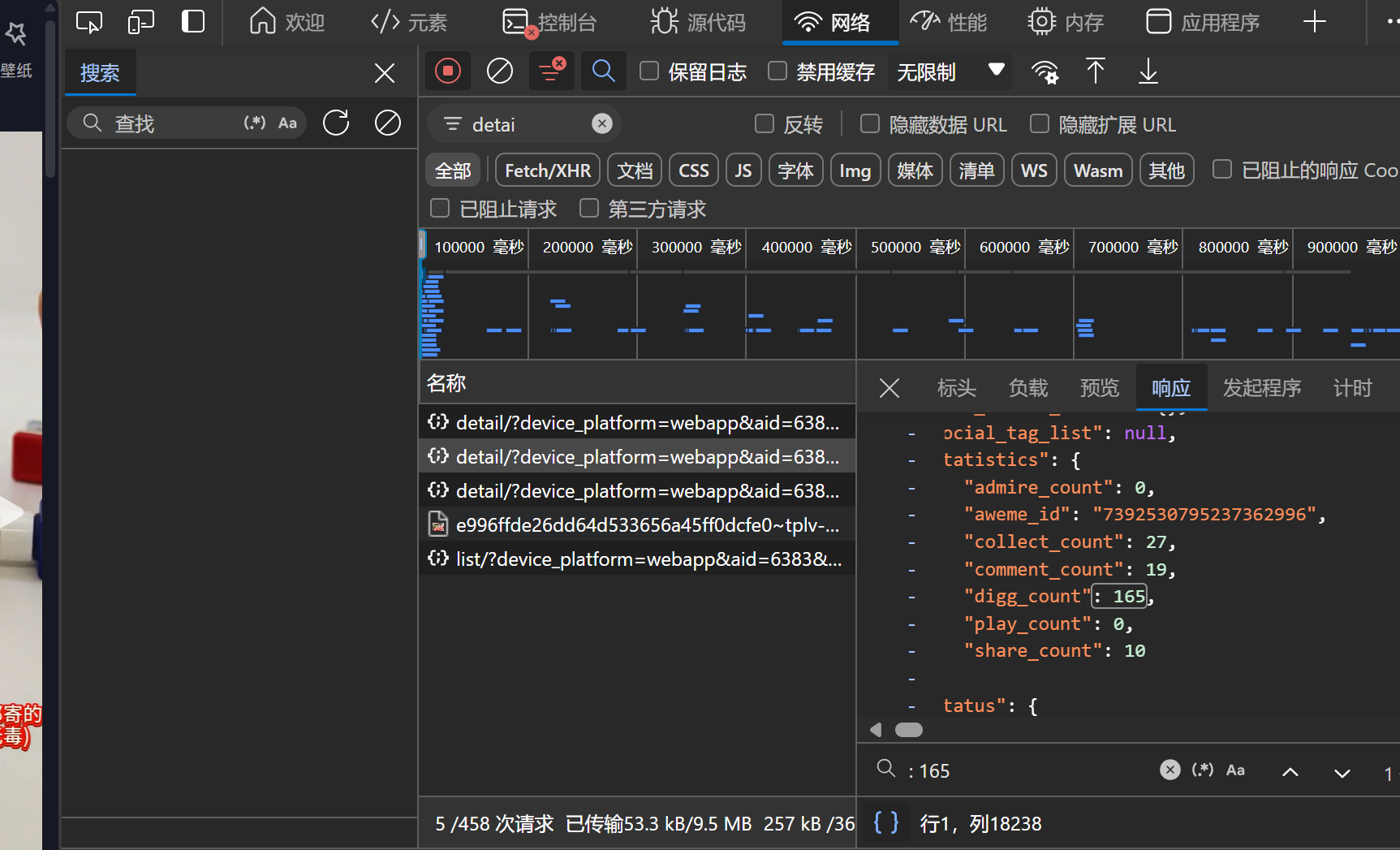
- 伪造http请求,发现返回数据为空,逐个修改请求参数发现逆向字段为a_bogus
1 | import requests |
- 通过对调用堆栈,使用XHR断点条件断点,控制台输出来确定加密代码的位置
- 拷贝加密代码,测试好之后使用execjs 调用
一些静态网站也可以直接发http请求之后分析html元素,一些知名网站可以直接在网上搜索逆向分析
4.方案二
模拟浏览器点击网页
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import time
import lxml
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
options = Options()
options.add_argument("--incognito")
options.add_argument("--mute-audio")
# 无窗口模式,更多参数参考资料2
if HideBroser:
options.add_argument("--headless")
options.add_argument("--disable-gpu")
service = Service()
browser = webdriver.Edge(service=service, options=options)
browser.get(url=url)
time.sleep(sec)分析网页标签重点,发现点赞数总是位于data-e2e=video-player-digg的标签的第二个子div标签下,故而提取数据
1
2
3
4
5
6
7
8
9import lxml
from bs4 import BeautifulSoup
tag = 'data-e2e'
key = 'video-player-digg'
soup = BeautifulSoup(browser.page_source, 'lxml')
base_tag = soup.find('div', attrs={tag: key})
children_tag = father_tag.select('div')
result = children_tag[2].text
参考文献:
 wechat
wechat